

An uncompromising guide to sleep masks (for side-sleepers)

For the last 8+ years, I’ve worn a sleep mask. As a light sleeper, sleep masks help me sleep and nap more consistently in more environments.
Over time, I’ve tried many in search of the best, since I’ll be wearing one for literally a sixth of my life1. I’ve found that the design space for excellent side sleeping masks is very restrictive: there’s some key features to look for in a great mask.
This post contains no affiliate links. I have no sponsors, purchased these with my own money, and will not hold back my hot takes about these masks. My goal is to share what’s worked well for me2, and hopefully help you find the mask of your dreams (har).
Aside: I view both sleep masks and earplugs as habit and dependency forming sleep aids. Once you adopt them into your sleep regimen, it can be difficult to undo, because your sensory thresholds will change. There can be detriments, too: unwashed masks can irritate your eyes and skin, and earplugs worsen situational awareness in emergencies. Personally, it’s worth it to me because staying asleep longer has huge impact on my quality of life.
What makes a great side sleeping mask
For side-sleeping, the single most important factor for comfort is thinner masks and straps. Thicker material presses against the ears and temples, particularly with firm pillows. Bulkier masks also sleep hotter during the summer, so less material is an all-around win.
Another challenge unique to side-sleeping is mask deformation when pressed against a pillow. This causes masks made of stiff or structured material to fail to block light around the nose. An ideal mask has ample nose and side coverage to prevent gaps, and squishes without pulling nearby material out of position.
Masks with raised eyecups are more comfortable because they leave air space around the eyes. Some even allow you to open your eyes completely and look around without resistance. Of course, most shaped masks crush and press on the side of your head against the pillow, but that eye was gonna be touching a pillowcase anyway.
With a few exceptions, most masks let a tiny amount of light in at the nose. This is usually not enough to notice with eyes closed, but some masks cover the edges better than others.
After spending lots of time wearing both synthetic and silk covered masks, there’s no contest: silk is far more comfortable and cooler against the skin than most synthetics. Some masks claim to be machine washable, though hand washing is so easy that it doesn’t matter much.
I’ve found masks with two straps to be more comfortable, because they can be made thinner and rest further from the ears and temples. Two-strap masks also tend to stay in place better.
Finally, straps with sliding buckles are preferable to velcro. The hook side of velcro straps has damaged several of my pillowcases over time, and the noise of opening the velcro to tighten or loosen it can disturb other sleepers.
My favorite mask: Alaska Bear Silk Contoured Sleep Mask
- Hybrid silk and molded foam, better than the sum of their parts!
- Lightweight and blocks light well when worn loosely
- Single silent sliding strap

| Price | $19.99 |
| Material | Silk + foam |
| Strap | Single sliding |
My current favorite mask is the contoured version of Alaska Bear’s silk sleeping mask. This mask is extremely comfortable on its side, blocks light well, and does so with minimal pressure. The best of most worlds, save for the single strap.
This mask is a hybrid of two very popular designs: it’s a molded foam mask clad in silk. This makes the skin-touching material cool and comfortable, while keeping it from pressing directly against the eyes. Unlike some contoured masks, I find there’s not enough room to fully open my eyes without my eyelashes brushing the inside, but it’s much more comfortable than a non-contoured mask.
This mask is less wide than most, resting more on the front of the face. This is nice for side sleeping because there’s less material pressed between the side of my head and the pillow. It’s not the thinnest mask (Alaska Bear makes a thinner silk one, reviewed below, which also wears cooler), but the silk helps this mask feel less bulky and hot than other foam masks.
Another interesting side-effect of the silk surround is it provides an extra soft layer which conforms to the face better and fills gaps. This makes the mask handle deformation unusually well compared to other contoured masks. Only a tiny amount of light comes in under the nose, even when pressed from the side.
The only thing I miss from this mask is a dual strap version. The single strap is pretty good: made of thin and soft elastic with a silent sliding buckle for adjustment. However, it doesn’t prevent the mask from riding up. When this mask is adjusted large, the strap buckle can annoyingly press into my ear, limiting the usable adjustment range.
Ok. Now that you’ve seen the best, let’s review the two worst sleep masks I’ve ever worn (they’re also the two most expensive!)
Tempur-Pedic Sleep Mask
- Horrible
- Super bulky with hard stitched seams
- Blocks all light, only when worn uncomfortably tight


| Price | $29.00 |
| Material | Velour + foam |
| Strap | Single velcro |
This was a surprise, since this mask is popular and many folks swear by it on reddit. At first I wondered if I’d received a lemon or a counterfeit, but my mask matches what I see on YouTube.
The strap is the widest I’ve ever seen (over 1”!) and made of loud scratchy nylon. Unlike most shaped masks which use molded foam, this mask has pleats and pouches sewn into it to form an eye gap. The eye gap is only somewhat effective: while there’s no direct eyelid pressure, my eyelashes brush against the inside and the lower lip digs into my lower eyelids.
The thick blue velour-like surface material is stitched together into firm seams which painfully press into my cheekbones when rested upon. The fabric is a dust and lint magnet. The front mask material loops back behind the ears, which can be painful since it’s so thick and noncompliant. It should go without saying that this mask sleeps hot.
The only positive thing I can say about this mask is if worn tight enough (increasing the clamping pressure on the cheekbones) it has very effective blackout, with basically no light leaks even in movement. When worn looser, the mask leaks light at the forehead.
The Tempur-Pedic mask ships with a comically large label attached which you must cut off. I don’t understand how many of these aspects could’ve been designed without a baffling indifference to the wearer.
Manta PRO Sleep Mask
- Unbelievably luxurious tech fabrics at an unbelievable price
- Over-designed and bulky, but perfect blackout
- Caused me to wake up seeing double 🔥

| Price | $79.00 |
| Material | Fancy synthetic |
| Strap | Single micro velcro |
Oh boy did I want to love this mask. The Manta Pro has the wildest, most ambitious, most interesting design of all the masks I’ve tried. It’s also 3x more expensive. Unfortunately it’s tied for last place with the Tempur-Pedic mask.
I bought the original Manta Sleep mask off a Facebook ad in 2018. The customizable eyecup design looked really clever, and it delivered on the promise of flawless blackout with no direct eye pressure. Alas, I never could get comfortable with the eyecups pressing against the side of my head. So a few years later, when Manta announced a fancy redesign specifically catering to side sleepers, I was very interested.
The construction of this mask is badass: to keep lightweight and cool, the strap is made of laser perforated foam wrapped with mesh. The parts that touch skin are made of deliciously soft and cooling tech fabric. And yet — there’s still way too much material in front of your face. Despite throwing the book at the original mask’s airflow problem, Manta Pro still feels hotter than most masks I’ve tried, probably due to the tight seal around the eyes.
Simply put, this mask is an iteration on a fundamentally flawed concept for side sleepers. The marquee feature of Manta masks is the repositionable eye cups which provide enough space to completely open your eyes inside them. Really cool! The problem is, if you move around while you sleep, especially on the side or front, the raised ridges around the eye cups can get offset, and now there’s raised ridges pressing directly into your eyes.
Several times after sleeping with this mask, I started my day with blurred vision due to pressure on the corner of my eye while I slept. I spent hours detaching, repositioning, and rotating the eyecups, figuring this was user error. I cranked that luxurious strap as tightly as I could to try to keep it in place. One day, I woke up seeing double: the pressure against my right eye had caused it to stop aligning with the left. At that point I concluded it was unsafe for me to continue using this mask.
If I was a back sleeper, this would probably be my endgame mask. It’s an amazing sitting up eyes open perfect darkness goggles… thing, but it’s not a good side sleeping mask at all. The Manta Pro convinced me that for side sleeping masks, less is more.
Which brings us to the ✨ Alaska Bear ✨.
Alaska Bear 2 Strap Sleep Mask
- Incredibly lightweight and breathable
- Double silent sliding straps are out of the way and can be worn loose
- Lack of structure presses against eyelashes, weird nose flap


| Price | $15.99 |
| Material | Silk |
| Strap | Double sliding |
Not to be confused with the contoured silk mask covered earlier, this Alaska Bear mask is simple and old school: it’s a thin pouch made of silk containing a sparse fibrous filler, with two straps to wrap it around the head. Because this mask is so thin and compressible, it’s almost unnoticeable when pressed between the head and pillow. It’s not thick enough to get in the way.
This was the first mask I tried made of silk, and it’s noticeably more breathable and comfortable against skin than the synthetic ones. The material of this mask is so thin that a small amount of light can shine directly through the mask — this is the only mask I’ve tried that does this. FWIW, I’ve spent a ton of time with this mask, and it was never a problem in bedroom lighting.
The straps on this mask are effectively perfect. Every sleep mask should have these straps. They’re imperceptibly thin, elastic, and have silent adjustment buckles for a customizable fit. Due to the double straps, the light weight of the mask, and the low friction material, this mask stays in position really well, even when worn pretty loose.
The lack of shape / structure in this mask is the main source of drawbacks. When worn, silk directly touches my eyelids and lashes, and opening my eyes is uncomfortable. This posed less of a problem while sleeping than I anticipated. Also, it’s difficult to figure out which side of this mask is the front; the only discernible difference is the strap and nose flap stitching bias slightly inwards when the tag is on the left side.
This mask has a little extra fabric under the nose bridge which is intended to form a gasket to block light leaks around the nose. It only works so-so in practice, and makes donning the mask more cumbersome because it must be flipped up to work. I still often had light leaking from below my nose due to the lack of a contoured shape.
Even with its flaws, this mask was my favorite for a long time owing to its simplicity.
Bedtime Bliss Sleep Mask
- Inexpensive and effective contoured mask
- OEKO-TEX certified materials, maybe?
- Giant branding on the front, loud velcro strap

| Price | $7.99 |
| Material | Bamboo/cotton + foam |
| Strap | Single velcro |
The Bedtime Bliss is a simple foam contoured mask with a single velcro strap. This mask has the best geometry for me of the molded foam masks (of which you’ll see there are many), perhaps owing to the wide ridge around the eye cups making good contact. The deep contour allows me to fully open my eyes and blink without any resistance. The mask shape also does a decent job blocking light leaks around the nose, though I still get a tiny amount. More light can leak when this mask is deformed or pulled by a pillow. The strap is a basic single elastic band with loud velcro fastening.
This was the first mask I wore consistently and I have long term experience with it. Overall, I still like this mask and would happily wear it, though I find the material less pleasant than silk masks. Bedtime Bliss claims to be made of OEKO-TEX certified materials, though it misspells that several times on the Amazon page. The mask used to be sold with a blank black front, though now it’s emblazoned with a huge logo under the left eye.
The fabric on the outside of this mask tends to come unglued over time, revealing gray foam, though the mask still blocks light fine. The velcro strap has exposed hooks on the back of the mask, which has scratched my pillowcases and caused them to pill. An easy fix is to cut the end of an old mask strap and stick it to the hooks, covering the gap.
Alaska Bear 2 Strap Contoured Sleep Mask
- Double silent sliding straps ❤️
- Doesn’t fit my face: always leaks light at the bottom
- Expensive, but nice materials

| Price | $19.99 |
| Material | Synthetic + Foam |
| Strap | Double sliding |
A foam contoured mask with double slider straps? Sounds amazing. Unfortunately, the shallow nose bump and eyecup shape don’t fit me. It might fit you better, though. The straps on this mask are absolutely perfect, like the other two-strap mask made by Alaska Bear.
Most foam molded masks are cheap enough that you can buy a bunch and pick the best, but this one is anomalously expensive. There doesn’t appear to be anything special about its construction: it’s another foam base with synthetic fabric glued on top.
This mask is a good example of the issues with contoured masks and variations in face shape. There is no combination of position or strap tightness I can find that doesn’t leak heaps of light under the nose bridge. Same issue for my wife. Perhaps if you have a shallower nose bridge this mask could work better for you.
We’re now deep in the realm of molded foam masks with slight design variations. You can find heaps of these on Amazon. To round out this guide, here’s two notable ones.
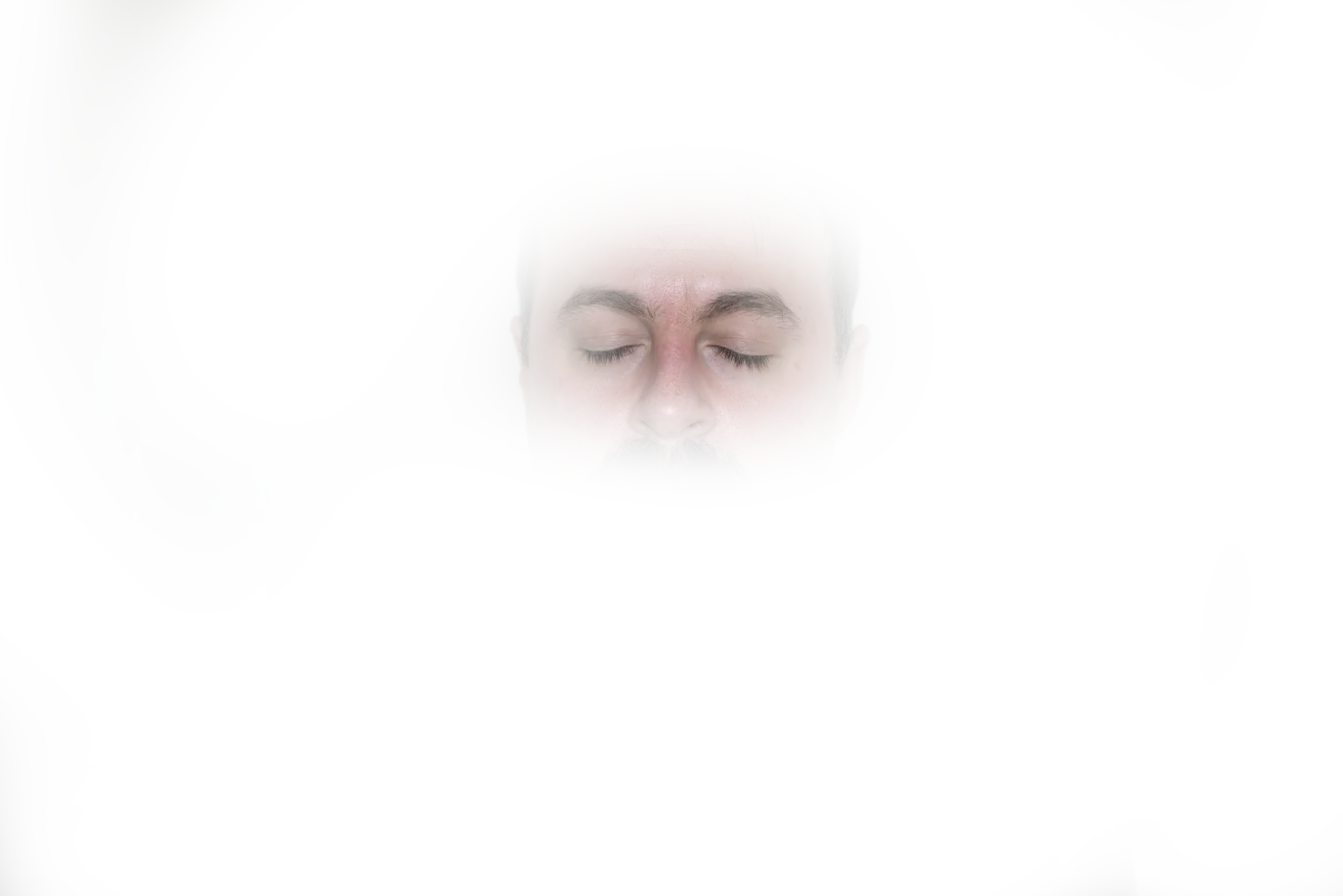
LKY DIGITAL “Sleep Mask for Side Sleeper” (lol)
- Cheapest option, comes in a pack of 3
- Nice materials, single silent sliding strap
- Great geometry but deep nose cutout leaks tons of light when deformed

| Price | $5.33 |
| Material | Synthetic + foam |
| Strap | Single sliding |
This is a really nice mask, save for a fatal flaw when side sleeping. Ironically, this mask is marketed specifically for side sleepers.
The mask has the largest, flattest nose cutout of any I’ve tried, and it works pretty well sitting up: regardless of nose size, only a tiny amount of light peeks by. However, as soon as there’s any pressure from the side, this mask transforms into the leakiest one on this list. Making matters worse, the leaked light is centered in view due to the high cutout, unlike most other masks where bottom leaks are in the periphery. In the photo above, you can see how the gap goes right up to between my eyes. For me, this is a total dealbreaker.
Otherwise, this mask has a lot going for it. Even though it’s inexpensive, it doesn’t feel cheap. The material is soft and the eye cups have a nice shape to them. It even has a decent sliding strap! If this mask had a different nose cutout with more coverage, it’d be a solid recommendation from me.
Bucky “40 Blinks” Sleep Mask
- Wide & deep cups give eyes space when pressed against pillow
- Many printed designs available
- On the expensive side, loud velcro strap


| Price | $12.00-17.99 |
| Material | Synthetic + foam |
| Strap | Single velcro |
The Bucky is superficially similar to many other molded foam masks in this list, but it’s wider and has deeper eye cups. It also comes in a variety of nice looking printed designs. The extra large eye cups do a remarkably good job at keeping pressure off the eyelids. Even when I intentionally jam my head into a pillow, I can open my eyes fully without any eyelash contact.
This comes with a tradeoff, though: due to its larger size, I find the Bucky is a bit more liable to shift on my head due to it making more contact with the pillow. The Bucky has a similar deformation problem to other molded form masks when side sleeping, with moderate light gap opening up at the nose.
This mask unfortunately has a loud velcro fastener, which may disturb anyone around you during late night adjustments. Bucky sensibly puts their logo on a small fabric tag by the strap (looking at you Bedtime Bliss). This mask is quite good as far as molded masks go, though the Bedtime Bliss offers similar performance at half the price.
Bucky also sells an “Ultralight” sleep mask which looks suspiciously similar to the LKY DIGITAL mask, high nose gap and all.
Final remarks
If you read all the way to the bottom, perhaps you share my strange obsession with sleep masks.
Did I miss your favorite one? I’d be happy to try other masks out (which offer something distinct from the ones above) and add to this list.
Drop me a line on Mastodon, or you can email sleepy@chromakode.com.
As for my overall recommendations, if you scrolled to the bottom looking for them:
For the best all-rounder side sleeping mask, I prefer the Alaska Bear Silk Contoured.
If you want the lightest and coolest, the Alaska Bear 2 Strap Silk is excellent too.
An economical foam alternative would be the the Bedtime Bliss sleep mask.
These have worked best for me, but a different mask might suit your personal preferences and head shape better. If you’ve had a different experience with any of these masks, I’d love to hear about it. Hopefully this guide has offered some useful jumping off points.
Sweet dreams!
(further discussion on Tildes)












